Small Sample Bias and Data Ethics
Many older works of once recognised scientific literature are now being deemed unreliable due to small sample bias. An increasing amount of meta-analyses are identifying unreliable fields of study, citing lack of reproducibility in larger sample sizes.

Notes on inflated correlation values in small samples
Thanks to Derek M. Jones for providing samples in other areas of academic study like software engineering and pointing me to a nice article from the apa on ‘Weird Findings’.
Many older works of once recognised scientific literature are now being deemed unreliable due to small sample bias. An increasing amount of meta-analyses are identifying unreliable fields of study, citing lack of reproducibility in larger sample sizes. It seems likely that we will face increasingly difficult ethical questions about large data collection as academicians attempt to check or re-verify their past claims with larger samples. Do we expect academic institutions to be put under pressure to ignore data-ethics in the future in an effort to correct for small sample bias?
As an example, I will discuss practical and ethical concerns to do with recent studies that involve imaging the brain to predict behaviour. Several meta-analyses have shown that studies linking brain to be unreliable. These concerns are also relevant to other studies that have been subject to recent criticism for having sample sizes that are too small. After looking at some criticism of small sample sizes used in the literature, I anticipate that in the future there will be an increased push to use data to validate studies.
A lot of Brain Imaging Studies might’ve been BullS**t this whole time
In a shocking turn of events, it appears that results in studies that link brain imaging to behaviour might not have been robust as we’ve once thought. In a shocking Nature article, Scott Marek puts forward an argument that brain studies might need thousands, not hundreds, of data points to be reliable. Brain imaging studies previously have only used dozens to hundreds of samples. However, Marek argues that these studies tend to not be replicable.
The paper is entitled “Reproducible brain-wide association studies require thousands of individuals”.
What sparked this inquiry? Scott Marek took a very large dataset of brain scans and behaviour, split it in two, and found that the results had opposing conclusions. This is an indicator that we might need larger datasets to validate results in this field. As Nature writes
“As a result, the conclusions of most published ‘brain-wide association studies’ — typically involving dozens to hundreds of participants — might be wrong. Such studies link variations in brain structure and activity to differences in cognitive ability, mental health and other behavioural traits.” [2]
To check this, the authors of the article first took a very large dataset of brain scan data. Then, they simulate studies with smaller subsets of this big dataset. It turns out, for smaller sample sizes, that reproducibility of experiments. With studies with lower samples, with less than 500 participants, there was only a 5% chance of reproducibility.
Using r-values
In these studies, researchers use a metric called an r-value which is a measure of correlation between two quantities. We can do an experiment as follows — let’s take unrelated things and then measure the correlation of subsamples — what are the chances of getting a positive result?
In this experiment we sample two independent normally distributed random variables. We first collect a sample of 10000, and then get subsets of this data which are sized at 100 samples without replacement. We repeat this subsampling 1000 times, and then measure the correlations between these subsamples. What does the distribution of correlations look like? I’ve plotted a histogram below. In this case, it appears we’re more than 30% likely to report a correlation with absolute value of more than 10%.

General ethical concerns on computational diagnostic studies
In the field of computational biology and medicine, I have read several pieces of research that use AI, ML and other statistical techniques to make diagnostic predictions from image data outright, or an images associated measurements. An example would be the dataset here. By diagnostic prediction, in this context I don’t mean technology that aids a doctor in seeing pictures more clearly, but rather makes a quantitative prediction on some part of the patient’s issues.
For example, there are studies which dedicate time to figuring out the function which maps data to some sort of truth. In a more abstract sense, this is essentially coming up with a function that tries to map some data to a diagnosis.
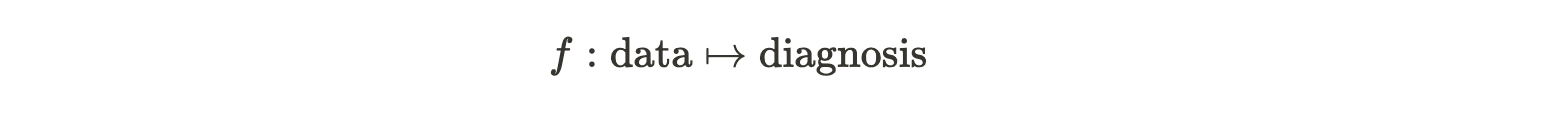
Ethical issues are not restricted to the process itself of making a prediction. By association, there are also issues in collecting data itself, since the data can be used in studies about the inference of f. One example is using brain images to examine the link between brain formation and behaviour. In this post, I wanted to discuss the ethics and reliability of these sorts of tests, and why I think overall that these types of studies do more harm than good.
In a future post, I wanted to examine the ethics of this kind of research through the lens of reliability — is it ethical to do research that we currently now know is unreliable?
This is a bit of a weird question to be honest.
How do we know something is unreliable?
Do we need more meta-analyses to test?
I think that the field in general needs larger sample sizes to be reliable. Since larger samples are required, it is more likely that some ethical questions need to be raised, since more data needs to be collected.There are several points that I wanted to unpack here, a few of which are mentioned in the excellent article on the ethics of digital pathology by Sorell T, Rajpoot N [1]. One of the points is unexplainabilty of black-box models. The next point is the vested interests of scanning technology companies. The last point will be on the data-ethics of the matter.
Other thoughts
Are there other fields of science that we feel are susceptible to this kind of error shown in the paper? I doubt that this is the only field of study. I posed this as an open question on LessWrong [4].
References
[1] Sorell T, Rajpoot N, Verrill C. J Med Ethics 2022;48:278–284.
[2] https://www.nature.com/articles/d41586-022-00767-3